Lammps Cmake安装记录
这篇文章记录使用Cmake安装Lammps过程
目标编译的包
- mpi并行
- kokkos
- GPU
- Voronoi
- Reaxff
系统信息
- win11下的wsl2,ubuntu 22.04
更新
- sudo apt update
- sudo apt upgrade
安装基础依赖
1 | sudo apt install cmake build-essential \ |
安装lammps
此处我们下载stable版本
1
wget https://download.lammps.org/tars/lammps-stable.tar.gz
解压
1
tar xvf lammps-stable.tar.gz
进入lammps目录,建立build文件夹
1
cd lammps-2Aug2023/ && mkdir build && cd build
编译Lammps
首先我们测试编译最基础的部分
1
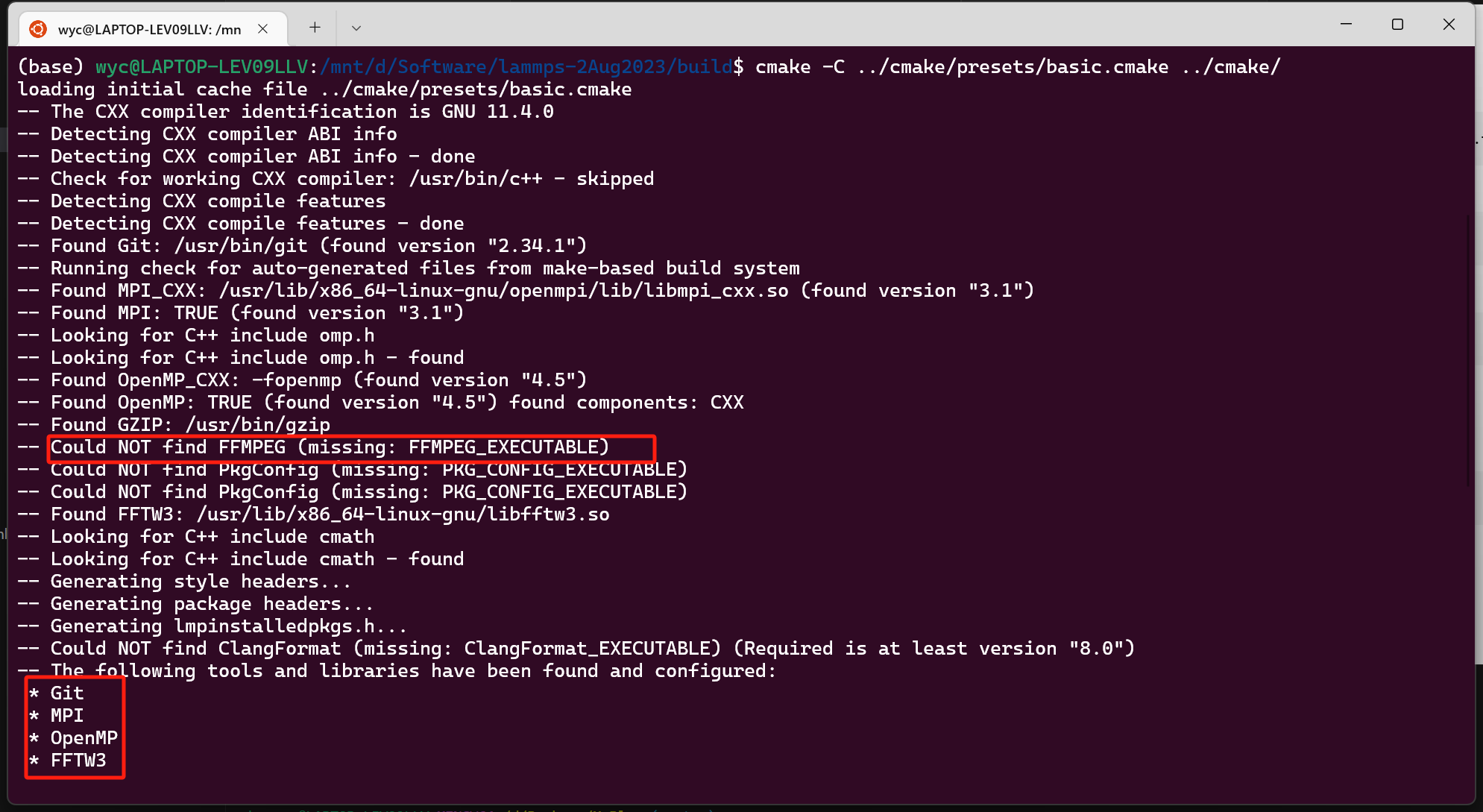
cmake -C ../cmake/presets/basic.cmake ../cmake
生成makefile

这里有几个重点可以看见,比如FFMPEG这个依赖我们没有安装,所以没有找到,这个依赖主要适用于一些图片,动画的处理,对于我们来说是不需要的,所以不需要安装,下面显示我们需要安装的有openmpi, MPI, FFTW。这些都是计算相关的,是我们需要注意的。编译
1
make -j 8
这一步是实际编译过程,-j 8代表使用8个核来编译。
测试
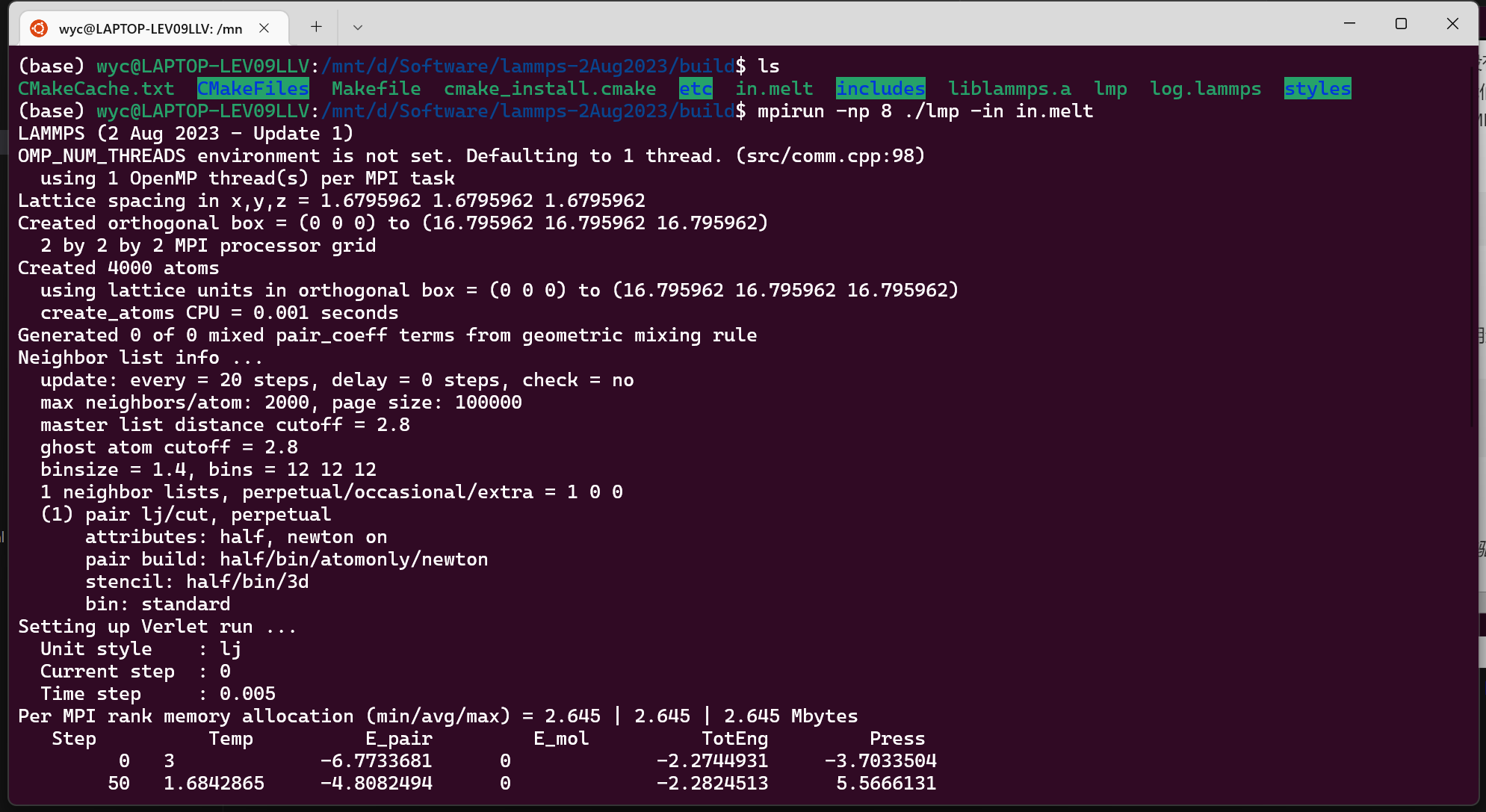
编译完成以后文件夹下就会生成一个可执行文件 lmp,使用这个便可以进行计算。1
2cp ../examples/melt/in.melt .
mpirun -np 8 ./lmp -in in.melt瞬间就完成了计算
个别库的安装
实际上到这里并行版本的lammps安装已经完成了,但是lammps包含了很多额外的库,很多是需要手动安装的,接下来我们来安装几个常用的库。
- 使用cmake编译不要和老版本的make安装混用,如果之前使用过make machine这样的方式,需要使用make no-all purge来卸载掉所有文件,需要保持src目录干净。
安装GPU驱动
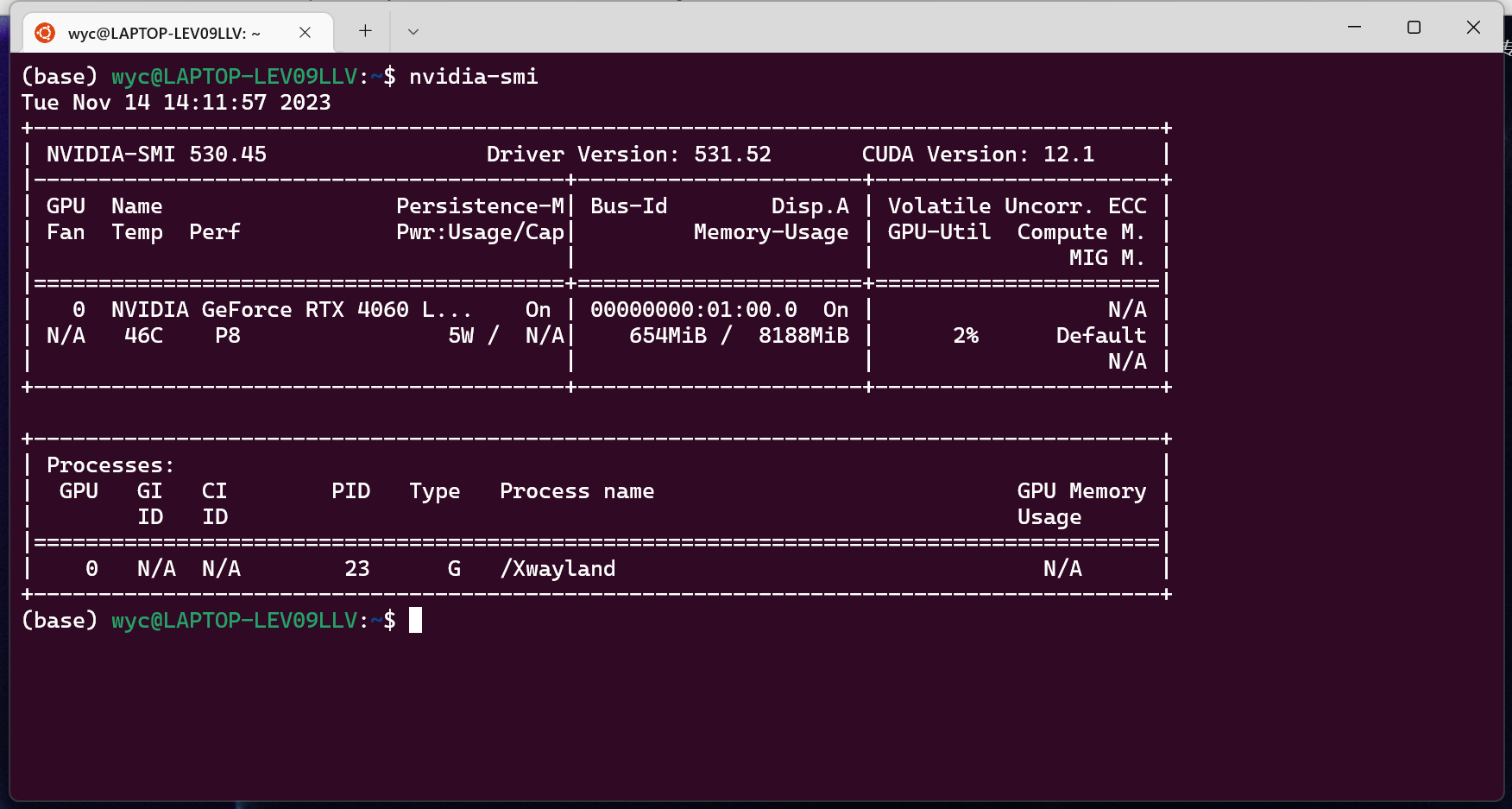
- 在windows环境更新显卡驱动,不要在wsl2环境再次安装驱动。
- 使用nvidia-smi检查显卡驱动版本
在wsl2中安装cudatool-kit,和驱动版本保持一致,我这里是12.1
1
2
3wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
sudo sh cuda_12.1.0_530.30.02_linux.run添加环境变量
1
2export PATH="/usr/local/cuda-12.1/bin:$PATH"
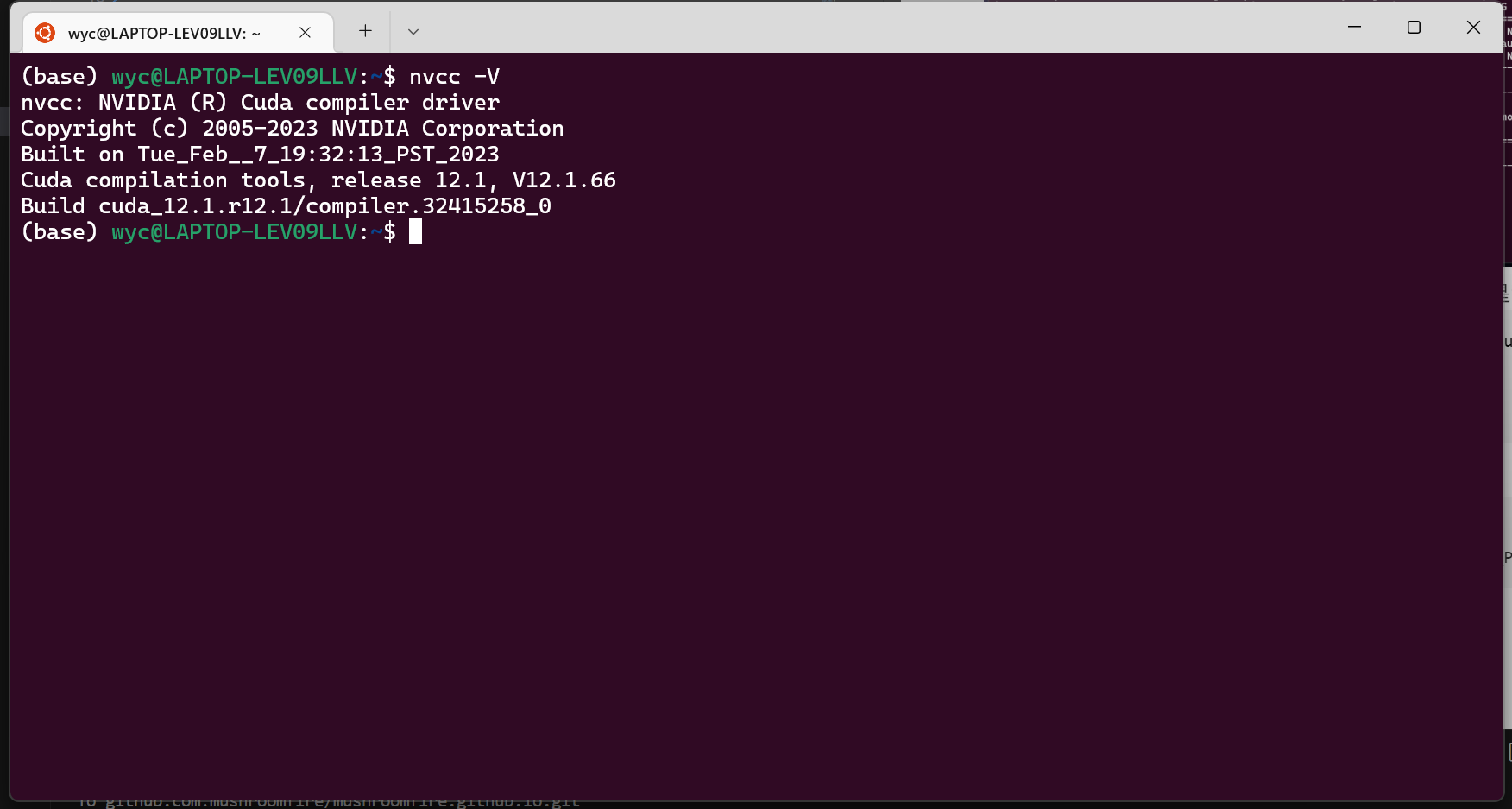
export LD_LIBRARY_PATH=/usr/lib/wsl/lib:$LD_LIBRARY_PATH检查是否安装成功
1
nvcc -V
编译GPU,Kokkos,Reaxff,VORONOI
修改../cmake/kokkos-cuda.cmake中的ARCH为ADA89 (40系列显卡都是这个架构)
1
2
3
4
5
6
7
8
9
10
11# preset that enables KOKKOS and selects CUDA compilation with OpenMP
# enabled as well. This preselects CC 5.0 as default GPU arch, since
# that is compatible with all higher CC, but not the default CC 3.5
set(PKG_KOKKOS ON CACHE BOOL "" FORCE)
set(Kokkos_ENABLE_SERIAL ON CACHE BOOL "" FORCE)
set(Kokkos_ENABLE_CUDA ON CACHE BOOL "" FORCE)
set(Kokkos_ARCH_ADA89 ON CACHE BOOL "" FORCE)
set(BUILD_OMP ON CACHE BOOL "" FORCE)
# hide deprecation warnings temporarily for stable release
set(Kokkos_ENABLE_DEPRECATION_WARNINGS OFF CACHE BOOL "" FORCE)Cmake命令如下:
这里GPU_ARCH数字可以在这里查看,我是4060,对应就是sm_89.1
cmake -C ../cmake/presets/basic.cmake -C ../cmake/presets/kokkos-cuda.cmake -D PKG_GPU=on -D GPU_API=cuda -D GPU_ARCH=sm_89 -D PKG_VORONOI=on -D DOWNLOAD_VORO=yes -D PKG_REAXFF=on -D PKG_OPENMP=yes ../cmake
简单解释一下cmake命令,lammps中包含了很多的库,对于不需要额外依赖或者设置的库,比如REAXFF,只需要添加 -D PKG_REAXFF=on 就行了,对于其他的库,则可能需要添加不同的输入参数,具体可以在这里查看。
接下来就是很尴尬的一点,因为笔记本内存只有16G,且wsl2似乎内存管理很不好,我只能单核编译,需要很久,内存小,没办法,只能等着。
如果你内存32G往上,可以尝试make -j 4,我在另外一台ubuntu (124 G内存)上编译,开启-j 8,很快就编译好了。当然,如果不编译kokkos包的话,编译其他的还是可以随便-j 8 跑的,这样速度就很快了,从我测试结果来看,笔记本是很不适合安装kokkos的。还有一个很大的坑,如果现在直接编译,经过漫长的等待以后,会显示报错:
这个问题和kokkos包编译直接相关,我一开始看见网上说把第一个-C去掉,就不会显示这个报错了,我就测试了一下,经过漫长的编译以后,确实不报错了,但是基础的包比如MANYBODY也没有编译呀,当你再想编译的时候,又会继续报错。
然后我就想着应该是cufft这个lib没有找到,我一开始尝试把路径添加进去:
1
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
逻辑上感觉是可以的,但是还是不行。
然后我尝试了一下软连接:
1
sudo ln -s /usr/local/cuda-12.1/lib64/libcufft.so /usr/lib/libcufft.so
再次编译,这下终于OK了。
但是,我还要说但是,我在我原生的UBUNTU电脑上测试,根本不需要这个步骤,直接make -j 8很快就OK了,所以这wsl2????算了,接下来简单跑跑测试。
1
make
性能测试
这里跑一个eam的例子。
1
cp ../potentials/Cu_zhou.eam.alloy .
gpu.in文件内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18dimension 3
boundary p p p
atom_style atomic
units metal
lattice fcc 3.615
region 1 block 0 50 0 50 0 50
create_box 1 1
create_atoms 1 box
pair_style eam/alloy
pair_coeff * * Cu_zhou.eam.alloy Cu
thermo 100
fix 1 all nve
run 500测试了mpi并行和GPU加速和kokkos-GPU加速,计算命令如下:
MPI并行 16 cores
1
mpirun -np 16 ./lmp -in gpu.in
OpenMP并行 32 threads
1
./lmp -in gpu.in -sf omp -pk omp 32
GPU加速
1
./lmp -in gpu.in -sf gpu -pk gpu 1
kokkos-GPU
1
./lmp -in gpu.in -k on g 1 -sf kk
对于这个50w铜原子体系,16核CPU并行速度为0.545 ns/day;要知道7945hx已经是笔记本上最强的CPU了。GPU包加速跑出了2.95 ns/day的成绩;GPU包果然名不虚传,4060这计算性能也不错。而且实际上如果把thermo的频率降低的话还能计算更快,让更多的数据跑在GPU上,减少和CPU的数据传输就能提高计算速度。可是kokkos-GPU加速就很拉跨了,才0.579 ns/day, 有可能因为4060的双精度计算能力太拉了,kokkos只支持双精度目前,GPU则是在混合精度跑的。
当体系增大到200w原子后,kokkos-GPU显存占用5.4G,速度为0.145 ns/day。此时GPU包直接使用则会爆显存 (4060 显存8G还是不够看呀),于是我额外设置了neigh no,这样neighbor list就会在CPU端完成,当需要频繁更新邻域时候这样会降低计算效率,但是好处是可以节约显存,对于这个案例由于不需要更新邻域,所以在设置neigh no以后,显存占用降低到5.2G,计算速度依然保持在很高的0.61 ns/day, 吊打kokkos,遥遥领先!还有一点,在输出时候,kokkos中的Modify这一项居然高达60%,这应该是很不合理的,但是还没有找到在哪里设置。32线程的openmp速度为0.153 ns/day, 16核MPI并行速度为0.134 ns/day,确实弟中弟。
总结
最近LAMMPS一直在推Cmake安装,确实简单了许多,很多库的安装也会流程化,虽然可能会遇见一些bug,但是这条路远比之前的make安装方便了许多。







